前言
最近DeepSeek这玩意爆火,因为作为一个国产AI,强度直接可以刚OpenAI的ChatGPT,所以那帮子老美看不惯了,一帮子人攻击别人DeepSeek的注册接口。。。
所以蹭着这个风头,我来玩玩开源版的DeepSeek,不过由于财力有限,啥4090/5090我都没有,所以自然和32B及以上大小的模型告别了。。。
我自己平时有一台丐版Mac Mini M4,只有16G内存,用来跑跑QQ机器人,Emby媒体服务(配合VidHub看电影和动漫别问为啥不用Infuse,因为付费)。同时,跑着一些程序(Python表情包后端啥的),所以考虑到这一点,内存自然不敢跑满,就挑了个8b的模型。。。
运行环境
本次部署DeepSeek-R1的环境为最便宜的Mac Mini M4(16G统一内存 + 256G硬盘)版本。俗称丐版。
部署的模型为:deepseek-r1:8b
部署
1. 下载并安装Ollama
访问Ollama官网,下载Ollama客户端。目前Windows, macOS, Linux均支持。
本篇博客仅讲述macOS端部署过程,其它系统暂不说明(如果以后我在其它系统实操后会补充)。
下载完毕后解压,并将Ollama应用程序移动到Applications(应用程序)文件夹,双击打开。继续按照提示安装ollama终端程序即可。
2. 准备好科学工具,使用Ollama下载模型
注意,使用Ollama下载模型需要科学上网,在启动Ollama应用程序的情况 (即macOS顶部有Ollama图标) 下,打开终端(Terminal), 运行你想要的模型,它会自动下载,首次下载完毕会自动运行模型。
例如我需要的是deepseek-r1:8b,那么:
ollama run deepseek-r1:8b其它模型以此类推,只需要指定不同模型名称即可。
等待下载完毕后,它会自动运行该模型,并且启动命令行对话程序,此时可以与模型对话,如果它能成功回答,即为部署成功。
3. 配置Ollama
Ollama默认会指定用户文件夹生成模型等文件存放路径,如果想修改模型存放路径,可以参考这篇文档。
目前我自己也还在研究这一块,因为不影响模型使用,所以可以慢慢研究。
4. HTTP API
Ollama服务默认使用本地的11434端口作为API入口,并提供了类OpenAI接口,具体API文档请参考:API文档
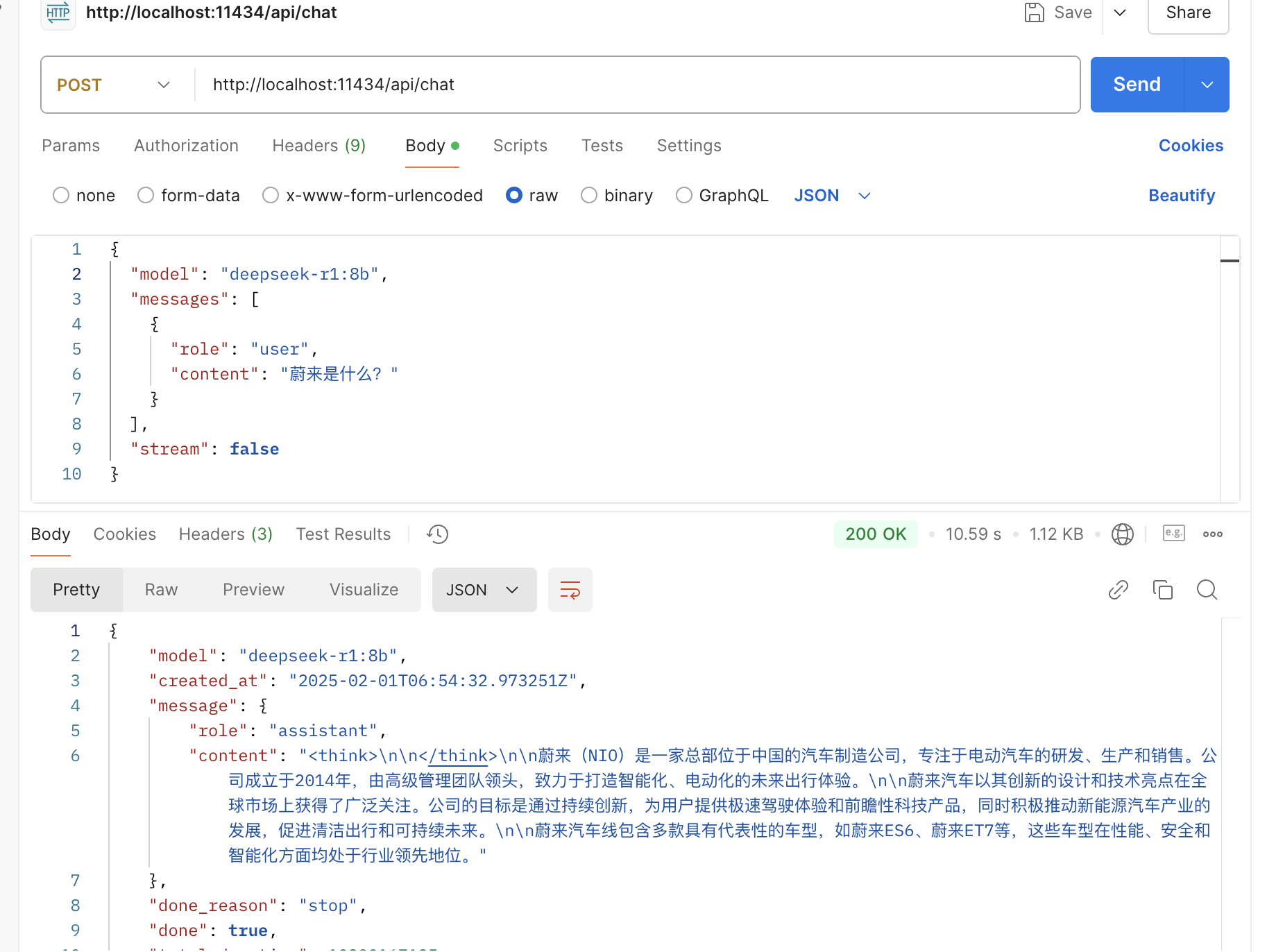
举例,跟模型进行单次简单对话,可以用Postman模拟请求
总结
经过以上步骤,就可以在macOS系统中搭建好一个本地化的deepseek-r1服务,此时,你可以考虑集成WebUI,或者自己基于HTTP API进行开发。